

So können sich Roboter energieeffizient orientieren
Damit sich Roboter autonom im Raum bewegen können, müssen sie abschätzen können, wo sie sich befinden und wie sie sich bewegen. Bislang war dies nur mit grossem Rechenaufwand und energieintensiv möglich. Ein Forschungsteam mit Beteilung der ZHAW-Forscherin Yulia Sandamirskaya hat nun eine neuartige energieeffiziente Lösung entwickelt und deren Anwendbarkeit auf eine reale Roboteraufgabe demonstriert. Die Ergebnisse wurden im renommierten Fachmagazin Nature Machine Intelligence publiziert.






Selbst kleine Tiere wie Bienen, die über weniger als eine Million Neuronen verfügen, können sich problemlos in komplexen Umgebungen zurechtfinden. Dabei nutzen sie visuelle Signale, um ihre eigene Bewegung abzuschätzen und ihre Position in Bezug auf wichtige Orte zu verfolgen. Diese Fähigkeit wird Visuelle Odometrie genannt. Punkto Kompaktheit und Energieeffizienz ist die Lösung, die Tiere einsetzen, unübertroffen im Vergleich zu den aktuell besten technischen Lösungen für Roboter. Damit aber neue Anwendungen wie kleine autonome Drohnen oder leichte Augmented-Reality-Brillen möglich werden, muss die Energieeffizienz massiv verbessert werden.
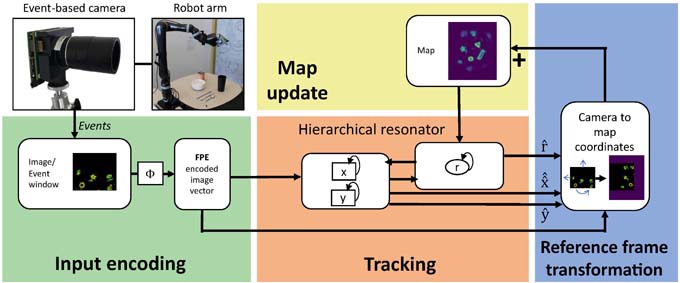
Nach dem Beispiel natürlicher neuronaler Netzwerke gebaut
In den Arbeiten, die in Nature Machine Intelligence publiziert wurden, schlagen ein internationales Team von Autorinnen und Autoren eine neue neuromorphe, also nach dem Beispiel natürlicher neuronaler Netzwerke gebaute Lösung vor, die sich auch effizient in neuromorphe Hardware implementieren lässt. Die präsentierten Ergebnisse stellen einen wichtigen Schritt auf dem Weg zur Nutzung neuromorpher Computerhardware für schnelle und energieeffiziente Visuelle Odometrie und die damit verbundene Aufgabe der gleichzeitigen Lokalisierung und Kartierung dar. Die Forschenden haben diesen Ansatz experimentell in einer einfachen Roboteraufgabe validiert und konnten mit einem ereignisbasierten Datensatz zeigen, dass die Leistung dabei dem Stand der Technik entspricht.
Mehr Transparenz in KI
Der grosse Unterschied zu heutiger KI, wie sie beispielsweise von ChatGTP genutzt wird, besteht darin, dass die beschriebene Methode verschiedene Komponenten einer visuellen Szene zu einer Komposition zusammenstellen bzw. auch auseinandernehmen kann. Bei den Komponenten handelt es sich um Informationen wie «Welche Objekte befinden sich darin?» oder «Wo befinden sie sich?» und viele weitere mehr. In den konventionellen neuronalen Netzwerken werden diese Komponenten miteinander vermischt und können nicht entwirrt werden. Die neue Methode kann das. Dies ist von entscheidender Bedeutung, um modulare und vor allem auch transparente KI-Systeme zu entwickeln.


